A tour of C++ 3장(i)
A tour of C++ 3장(i)
모듈화, 모듈, 네임스페이스에 대해 알아보자.
모듈화
C++ 프로그램은 독립적으로 개발된 여러 부분들로 구성된다. 구성요소로는 함수, 클래스, 템플릿, 클래스 계층 관계등이 존재한다. 이들을 관리하는데 있어 가장 중요하는 부분은 이들 간의 상호작용을 명확하게 정의 하는 것 이다. 상호작용을 명확하게 하기 위한 첫 단계는 “인터페이스” 와 “구현” 을 분리하는 것이다. 즉, 우리가 앞서 클래스를 구성할 때 보았던 것과 같이 사용자를 위해 오픈해주는 인터페이스와 인터페이스에서 필요한 동작을 하는 구현 부분으로 나누는 것이 중요하다.
C++에서는 선언을 기반으로 “인터페이스”를 표현한다. 선언은 함수나 타입을 사용하는데 필요한 모든 사항을 명시하는 것을 의미한다.
double sqrt(double);
class Vector {
public:
Vector(int s);
double& operator[](int i); // 후위 연산자 재정의
int size();
private:
double* elem;
int sz;
};
위와 같이 필요한 사항들이 선언 되고 나면, 핵심은 ‘어딘가에’ 존재하는 함수 몸체 즉, 함수 정의다. 인터페이스 내에서 동작하는 “구현” 부분의 정의를 확인해보자.
double sqrt(double) {
// 수학시간에 배운 알고리즘이 들어갈 것임. (간략화 :) )
return (double *dobule);
}
Vector::Vector(int s)
:elem{new double[s]}, sz{s}
{
}
double& Vector::operator[](int i)
{
return elem[i];
}
int Vector::size()
{
return sz;
}
함수를 비롯한 구성 요소를 여러 번 선언하는 것은 가능하지만, 정의는 오직 한 번만 가능하다. 우리는 선언과 정의로 나누는 것을 모듈화 한다고 하며, 모듈화 작업을 통해 상호작용을 어떻게 잘 할 수 있는지는 뒷장에서 차차 다루도록 하겠다.
분할 컴파일
C 와 동일하게 C++에서는 분할 컴파일을 지원하는데, 덕분에 사용자 코드에서 사용할 타입과 함수의 선언만 존재한다면 컴파일이 가능하다. 함수의 구현부는 외부에 있어도 선언부만 있다면 컴파일하는데 문제가 없음으로 프로그램을 “반독립적”인 코드 조각의 집합들로 조직화 할 수 있다.
이러한 분할 컴파일은 컴파일에 소요되는 시간을 최소화하며, 논리적으로 구분되는 프로그램의 분리를 강제화하는 장점이 있다. 구현부를 굳이 알 필요 없기 떄문에 코드를 작성하는 과정에서 에러를 줄 일 수 있다. 이런 컴파일된 코드 조각 (함수)의 묶음을 우리는 “라이브러리” 라고한다.
보통 선언부는 header file(.h)에 담고 구현 부는 cpp file (cc, cpp)에 담는다. 이후 include (인클루드) 작업을 통해 선언부에 정의된 함수를 접근할 수 있도록 한다.
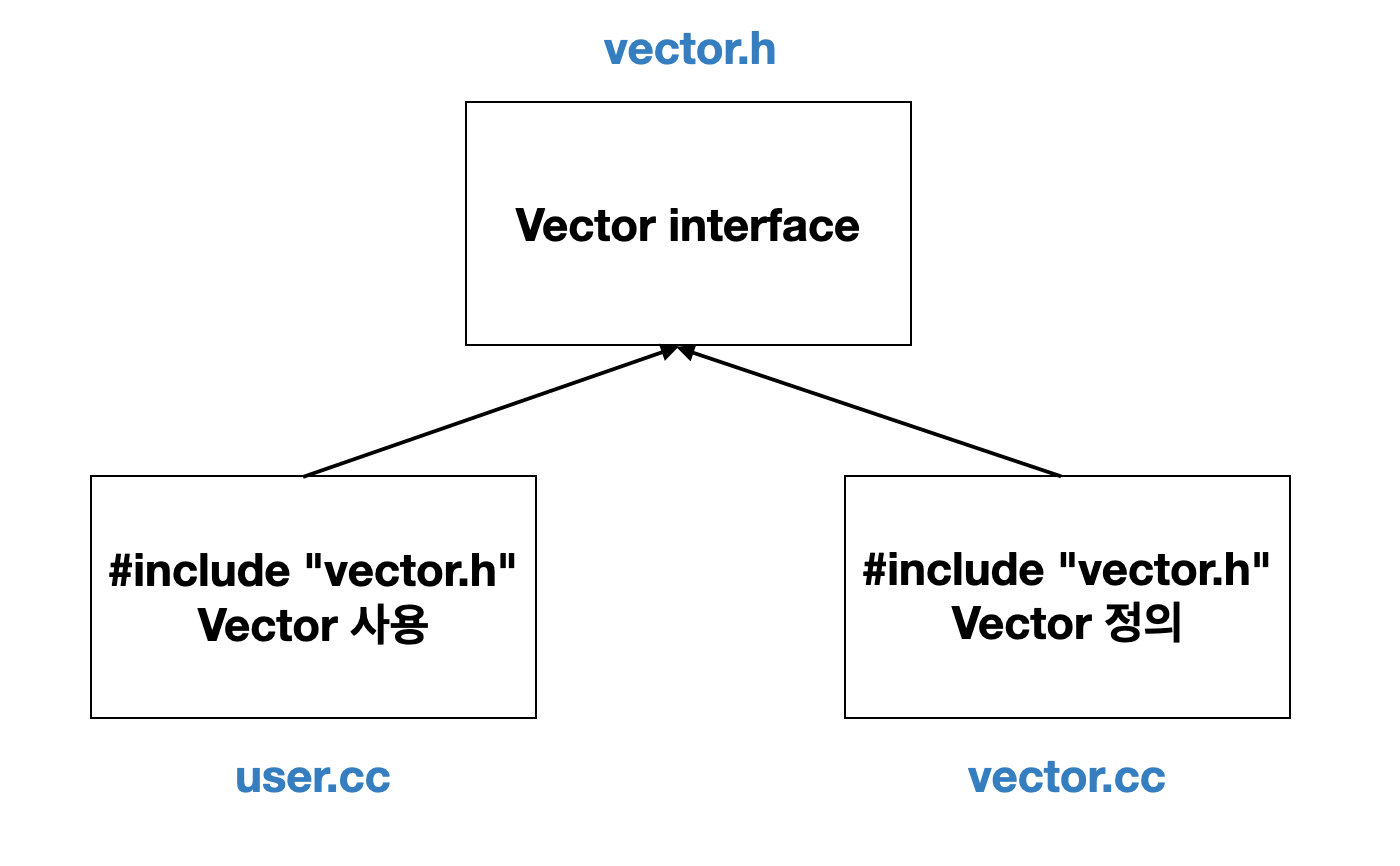
위의 그림과 같이, “정의”는 하나인 반면, 선언부는 다수의 파일에서 사용이 가능하다. 구체적으로, vector.h 파일의 정의부에서 정의한 함수같은 경우 user,cc 파일에서도 선언부를 참고해 사용이 가능하다.
g++ vector.cc
g++ user.cc
위와 같이 두 개의 .cc 파일은 컴파일 가능한 독립적인 파일이다. 우리는 이런 독립적으로 컴파일 가능한 .cc or .cpp 파일을 변환단위 (translation unit)이라 하며, 수천 개의 변환 단위가 한 프로그램을 구성할 수 있다.
모듈 (C++ 20)
프로그램을 여러 부분으로 구성하기 위해서는 수 많은 #include를 이용한 변환단위들이 필요하다. 이런 방법은 아주 오래되었으며, 에러의 소지도 크고 그에 따른 비용도 크다. 예를들어 101개의 변환 단위에서 #include “header.h”를 사용한다고 가정해보자. 만약 header.h 파일에서 변화가 발생한다면 compiler는 101개의 분한 컴파일로 인해 변환 단위를 전부 다시 컴파일 해야한다. 따라서 빌드 시간이 오래걸린다. 이를 해결하기 위해 ccache 등의 유틸리티가 등장해 빌드 속도를 높이려 열을 올리고 있다. 또한 #include 같은 경우 반독립적으로 컴파일 된다. 따라서 다른 header file을 include 하는 과정에 영향을 미치게 되고 이로 인해 에러가 발생한다.
이런 상황들은 당연 올바르지 않고, C에서 이런 방식을 채용한 1972년 이후로 수많은 비용 발생과 버그의 주요원인이 되고 있다.
C++20에서는 이런 문제를 해결하기 위해 module이라는 새로운 언어 기능을 추가했다.
일상생활 모듈 예시
모듈을 좀 더 쉽게 이해하기 위해 일상생활을 떠올려보자.
포도가 먹고 싶어 과일가게에 갔다고 생각해보자. 과일장수가 포도를 사기 위해서는 오렌지, 딸기를 한꺼번에 사야하고 가격은 동일하다고 한다. 나는 기분 좋게 포도, 오렌지, 딸기를 한꺼번에 사온다.
이걸 함수로 생각해보자.
cout을 사용하고 싶어 Library를 사용하고자 한다. 하지만, C++에서는 cout을 포함한 100개가 넘는 함수들이 묶인 iostream을 #include 해야 사용가능하다고 한다.
이를 해결하기 위해서 C++은 Module이라는 기능을 제공하며, iostream을 전체 include 하는 것이 아닌 특정 함수만 import해서 사용할 수 있도록 한다.
좀 더 프로그래밍 관점에서 생각해보자.
Java를 해 본 사람들은 “module”을 봤고 경험했을 것이다. 일례로 우리는 Java에서 text를 입력받기 위해 scanner 함수를 사용한다.
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
// console 참에서 입력 받는데 필요한 함수
Scanner sc = newScanner(System in);
int i = sc.nextInt();
System.out.println(i);
sc.close();
}
}
Java에서 Scanner 함수를 사용하기 위해서는 import 라는 것을 하는데 필요한 모듈만 우리는 import해서 사용한다. 구체적으로, java.util 전체를 import하는 것이 아닌 특정한 함수 모듈만 import해 사용한다. 따라서, 빌드시간과 각 종 발생할 수 있는 에러를 줄일 수 있다.
C++ module code example
아직 표준화 되지는 않았지만, C++20 module을 어떻게 사용해야하는지 예시를 보자.
// Vector.cpp 파일
module;
export module Vector; // "Vector 모듈정의"
export class Vector {
public:
Vector(int s);
double& operator[](int i);
int size();
private:
double* elem;
int sz;
};
Vector::Vector(int s)
: elem{new double[s]}, sz{sz}
{
}
/... 다른 멤버함수도 초기화했다 가정/
export int size(const Vector& v) { return v.size(); }
위 코드는 Vector라는 module을 정의하는데 사용한다. 클래스는 Vector와 그에 포함된 모든 멤버 함수 그리고 비 멤버 함수인 함수를 export 키워드를 이용해 노출 시킨다.
- keyword
- module : module 선언
- export : 외부에 노출 선언
- import : module include 역할
// user.cpp
Import Vector;
#include <cmath>
double sqrt_sum(Vector& v)
{
double sum = 0;
for (int i = 0; i != v.size(); ++i)
sum+=std::sqrt(v[i]);
return sum;
}
위의 user.cpp 코드를 보자. 위의 코드를 보면 Vector module을 Import하는 것을 볼 수 있다. 또한 눈여겨 볼 점은 include 동작도 병행해서 사용이 가능하다는 점이다. 아무래도 기존 코드들에 Import를 사용하기 위해서는 호환성 문제를 최소화 하고자 병행해서 사용하도록 한 것 같다. Import는 독립적으로 동작하기 떄문에 기존 코드들에 영향을 미치지 않는다.
또한, 비멤버 함수 size는 우리가 import 하지 않았기 때문에 사용이 가능하지 못하며, 현재 vector.size() 같은 경우 Vector 자체를 Import 하였기 때문에 해당 객체내 멤버 함수들을 사용하는 것이라 보면된다.
- 모듈 특징
- 모듈은 한 번만 컴파일 된다.
- 두 모듈을 import하는 순서가 코드의 의미에 영향을 주지 않는다.
- 어떤 모듈에서 무언가를 import해도 해당 모듈의 사용자가 내가 import 한 것에 대한 암묵적인 접근 권한을 갖거나 조작할 수 없다.
NameSpace
C++에서는 namespace 메커니즘을 제공한다. 우리는 이를 이용해서 일부 선언을 묶고 다른 파일에서 중복으로 사용하는 것을 허가한다. 즉, 이름 충돌을 막는다. 간단한 예시로 확인해보자.
namespace foo {
class foo_class {
main();
};
foo_class::main() {
cout << "foo_class" << endl;
}
} // namespace foo
int main() {
foo_class::main();
}
위 코드에서는 main() 함수가 두개 존재한다. 만약 namespace를 정의하지 않는다면, naming충돌이 나서 compile 에러가 발생될 것이다. 이를 해결하기 위해 foo_class를 foo namespace로 wrapping 한 후 사용하게 된다면 main()를 사용할 수 있다.
우리가 만약 namespace를 지정하지 않는다면 전역 namespace로 선언된다. 우리가 흔히 사용하는 main() 같은 경우 전역 namespace에 저장되어져 있다. 따라서, 우리가 추가로 main()를 구현하고 싶다면 꼭 namespace를 사용해야한다.
그렇다면 만약 전역 namespace의 함수를 호출하고 싶다면 어떻게 해야하는가?
class foo_class {
foo_main() {
cout << "hoho" << endl;
}
}
namespace foo {
class foo_class {
foo_main() {
cout << "haha" << endl;
}
}
}
int main() {
foo::foo_class::foo_main();
// 전역으로 함수를 호출하고 싶을 때
::foo_class::foo_main();
}
위의 코드와 같이 전역 namespace에 존재하는 함수를 호출하고 싶을 때는 :: 뒤에 함수명을 적도록한다. 즉, :: 연산자 앞에 namespace를 선언하지 않으면 전역 namespace에 있는 함수를 호출하도록 한다.
standard library를 활용한 표준 함수를 사용할 때 매번 네이밍을 붙이는 것이 귀찮을 수 있다. 이때는 using이라는 keyword를 사용하면 된다. using 선언 같은 경우 해당 이름의 함수를 현재 scope로 가져온다라는 의미이다.
void my_code (vector<int>& x, vector<int>& y) {
using std::swap;
swap(x,y);
}
위의 코드를 보면 standard library의 swap 함수를 using과 함께 사용한 것을 볼 수 있다. using을 사용할 경우 현재 scope로 변환되기 때문에 std:: namespace를 붙일 필요가 없다.
만약, 특정함수 뿐만아니라 library 내 모든 함수를 해당 scope로 변경하고 싶다면 아래의 코드를 추가하자.
using namespace std;
해당 코드를 코드 선언부에 작성해준다면 scope를 해당 코드 scope로 변경함으로 namespace를 추가해 줄 필요가 없어진다. 하지만, 위와 같은 방법을 한다면 언제 name 충돌이 발생할지 모르고 또 프로그램이 커지면 버그도 찾기 어려워 진다. 따라서, 간단한 코드가 아니라면 namespace를 다 적어주는 습관을 기르도록 하자.


