Multi thread 환경에서 Singleton을 디자인 하는 방법을 알아보자
이전 포스팅에 이어 추가적으로 보충할 내용을 작성한다. 이전 포스팅을 보지못한 사람은 여기 를 클릭해 확인해보기 바란다. 이전 포스팅을 읽은 후 아래의 포스팅 내용을 본다면 이해가 더 쉬울 것이라 생각한다.
Singleton pattern
우리는 저번 posting에서 singleton pattern을 만드는 3가지 방법에 대해 배웠다.
- static 멤버변수를 이용한 singleton pattern
- static 지역변수를 활용한 singleton pattern(lazy initialization 기법)
- pointer를 활용한 singleton pattern
3가지 singleton pattern 중에서 system의 환경을 받는 singleton pattern을 알아보고 최적화 시키는 방법을 구현해보자. 저번 posting에서도 간략히 언급하였지만, system 환경에 영향을 받는 singleton은 pointer를 활용해 디자인 했을 경우이다. 즉, single core냐 multi core의 환경에 따라 구현 방법이 달라>진다. 왜 그럴까 생각해보자. single core일 경우에는 thread가 오직 하나밖에 존재하지 않는다. multi core일 경우에는 다수의 thread가 존재한다. 이럴 경우 동기화 문제가 발생하게 되는>데 구체적으로 아래의 예시를 통해 알아보자.
Multi thread 환경에서 문제점
아래의 소스코드는 pointer를 이용해 Instance를 생성하는 코드이다.
#include <iostream>
using namespace std;
class Cursor
{
private:
Cursor() {}
Cursor(const Cursor&) = delete;
void operator=(const Cursor&) = delete;
static Cursor* pInstance;
public:
static Cursor& getInstance()
{
if(pInstance == 0)
pInstance = new Cursor;
return pInstance;
}
};
Cursor* Cursor::pInstance = 0;
int main()
{
Cursor& c1 = Cursor::getInstance();
}
Multi thread환경에서 pointer를 이용해 instance를 생성하는 부분에서 동기화 문제가 발생하는데 구체적으로 보자.
static Cursor& getInstance()
{
if(pInstance == 0)
pInstance = new Cursor;
return pInstance;
}
getInstance()함수 호출을 통해 instance를 생성한다. 하지만, instance가 초기에 없을 경우 new연산자를 이용해 새롭게 instance를 생성한 후 return한다. Multi thread환경에서 getInstance()를 초기(instance가 생성되지 않은 경우)에 호출하게 된다면 어떻게 될까?
- getInstance() 호출과 동시에 A-thread 는 함수를 수행하기 시작
- 동시에 일어나는 경우를 보자 2.1. 초기일 경우 instance가 없어서 new 연산을 통해 Cursor 객체 생성 2.2. 다른 부분에서 getInstance()를 요청함. 2.2.1. B-thread 는 함수를 수행함 2.2.2. Cursor객체가 만들어지지 않은 것 같아 new 연산을 수행함
위의 경우와 같이, A-thread가 new연산을 통해 Cursor 객체를 만들기 전에 외부에서 getInstance 함수를 호출하게 된다면 동기화문제 가 발생하게 된다. 동기화 문제가 발생하는 이유는 단순하다. Singleton 디자인 패턴 자체가 객체를 생성하는 부분을 공유해 오직 한 곳에서 생성하기 때문이다. 즉, “공유” 함으로 동기화문제는 따라오>게 된다.
동기화 문제를 해결하는 것은 단순하다. Lock연산을 이용하면 쉽게 해결 된다. C++11 에서는 mutex 라는 lock을 함수로 제공해준다. (좋은 세상이다..) Lock을 사용하기 위해서는 “mutex” 라는 헤더 파일을 이용해야한다.
#include <iostream>
#include <mutex> // 추가
using namespace std;
class Cursor
{
private:
Cursor() {}
Cursor(const Cursor&) = delete;
void operator=(const Cursor&) = delete;
static Cursor* pInstance;
static mutex m; // 추가
public:
static Cursor& getInstance()
{
m.lock(); // 추가
if(pInstance == 0)
pInstance = new Cursor;
m.unlock(); // 추가
return pInstance;
}
};
Cursor* Cursor::pInstance = 0;
mutex Cursor::m; // 추가
Mutex를 이용해 Lock을 사용하는 방법의 소스코드는 위와 같다. Lock을 사용하는 방법은 단순하다. 동기화 문제가 있는 부분에 Lock 함수를 호출해 자물쇠로 잠궈주고, 이후 동기화 문제가 >종료되는 부분에서 unlock을 통해 자물쇠를 풀어주면 된다. 다만, getInstance() 함수가 static으로 생성되기 때문에 lock 변수 또한 static으로 선언되야하며, 초기화 하는 부분이 생긴다는 점을 잊지말자.
DCLP (Double Check Locking Pattern)
이걸로 완료된 것일까? 아니다. 문제가 하나 존재하는데 생각해보자.
static Cursor& getInstance()
{
m.lock(); // 추가
if(pInstance == 0)
pInstance = new Cursor;
m.unlock(); // 추가
return pInstance;
}
위의 코드는 getInstance() 에 Lock을 적용한 코드이다. Lock을 적용할 경우 꼭 생각해야하는 부분이 있는데, Lock은 성능적 이슈가 존재하게 된다는 점이다. Lock이 동기화 문제를 막는다는 점에서는 정말 좋은 도구이지만, 성능을 기하급수적으로 떨어뜨릴 수도 있다는 단점이 존재한다.
위 코드 같은 경우, getInstance() 호출 할 경우 Lock 걸고 instance 존재 유무를 판단한다. 만약, 존재 유무를 판단할 때, 다른 thread들이 접근하게 될 경우 Lock이 풀릴 때까지 대기 해야한다. 대기를 한다는 것은 CPU 내 core들이 Lock을 얻기만을 기다리도록 해야한다는 점인데, 여러개의 프로그램을 관리하고 수행하는 CPU 입장에서는 엄청 부담스러운 일이다. 즉, getInstance() 호출할 때마다 프로그램의 성능이 엄청 떨어진다는 단점이 존재한다.
동기화 문제도 해결해야하고 성능도 지킬 수 있는 방법이 없을까?
이 문제를 해결하기 위해 고안된 기법이 DCLP (Double Check Locking pattern) 이다. DCLP 란 말그대로 Locking 동작을 두번 체크하는 방법이다. 코드로 확인하자.
static Cursor& getInstance()
{
if (pInstance == 0) { // 추가
m.lock();
if(pInstance == 0)
pInstance = new Cursor;
m.unlock();
}
return pInstance;
}
위의 코드는 DCLP가 적용된 코드이다. 코드가 많이 추가 된 것이 아닌 조건문 하나만 추가 되었다. 즉, Lock을 잡기 전에 pInstance가 존재하는지 확인하는 것이다. 이럴 경우 새롭게 생성할 필요 없는 경우 Lock을 대기할 필요가 없어진다.
DCLP의 장단점
- 단점 : if문을 두번 사용해야한다. 가독성이 떨어질 수도 있지만 크게 문제되지 않는다.
- 장점 : Lock을 기다리는 동작을 하지 않아도 되기 때문에 성능적 향상이 존재한다. if문 같은 경우 아닐 경우 바로 return 하기 떄문에 성능이 많이 향상 된다.
04년도 DCLP
DCLP는 90년대와 00년대 초반을 아우루는 핵심 기술이었다. 다만, 04년도에 DCLP에 문제가 존재한다는 논문이 등장하며 수정이 요구되었다. 어떤 문제가 있었을까?
// 코드의 공간을 줄이기 위해 생략한다. 완전한 코드를 보고 싶다면 위를
참고하자.
static Cursor& getInstance()
{
...
if(pInstance == 0)
pInstance = new Cursor;
...
}
getInstance()에서 중요하게 봐야할 부분은 Lock 함수 내 존재하는 Cursor를 만드는 부분이다. 컴파일러가 되어보자.
pInstance = new Cursor; 만들기 위한 컴파일러 관점
- 메모리 할당 = tmp = sizeof(Cursor);
- 생성자 호출 = Cursor::Cursor();
- 임시로 할당받은 메모리를 변수에 저장 = pInstance = tmp;
컴파일러 같은 경우 3단계로 나눠져 Cursor 객체를 만든다. 하지만 시대가 흐를수록 컴파일러는 똑똑해져서 동작을 최적화면서 문제가 발생하기 시작했다.
1. 메모리 할당 = tmp = sizeof(Cursor);
3. 임시로 할당받은 메모리를 변수에 저장 = pInstance = tmp;
메모리 할당을 한 후 바로 변수에 저장하자. 이 동작은 비슷하니까 연결하는게 좋겠다
하고 컴파일러가 최적화를 해버릴 수도 있다. 이후 생성자를 호출한다
2. 생성자 호출 = Cursor::Cursor();
위와 같이 최적화할 경우 어떤 문제가 발생할까?
생성자를 호출하지 않아 객체가 생성되기 전 다른 thread가 객체가 없는 줄 알고 Lock을 획득하려 할 수도 있다.
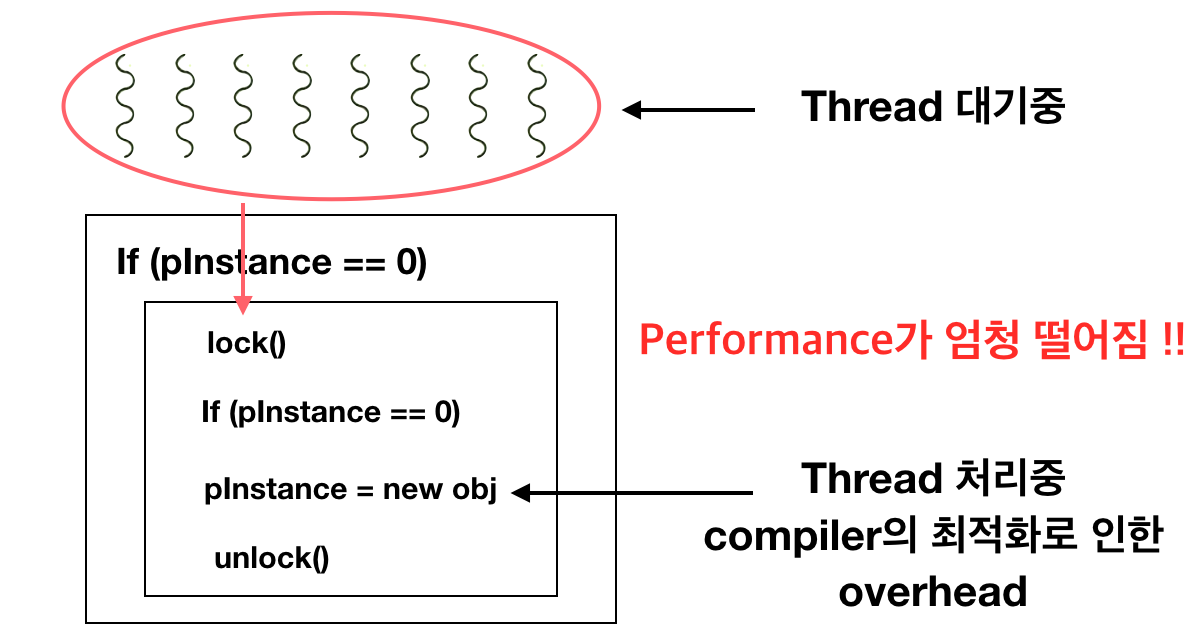
위의 그림을 통해 문제를 분석해보자. 그림에서 나온 것과 같이, compiler의 최적화를 통해 객체의 생성자를 부르기 전 다수의 thread가 호출될 수 있다. (극단적 상황고려..) 그럴 경우 엄청난 overhead가 발생하게 된다. 이를 해결하기 위해서는 compiler에게 reordering을 금지하도록 명령해야한다. C++11에서는 atomic 연산을 할 수 있는 api들이 등장했다. Api들은 atomic 헤더파일 내 존재한다.
#include <iostream>
#include <mutex>
#include <atomic>
using namespace std;
class Cursor
{
private:
Cursor() { }
Cursor(const Cursor&) = delete;
void operator=(const Cursor&) = delete;
static mutex m;
static atomic<Cursor*> pInstance;
public:
static Cursor& getInstance()
{
Cursor *tmp = pInstance.load();
if (tmp == nullptr) {
lock_guard<mutex> lock(m);
tmp = pInstance.load();
if(tmp == nullptr) {
tmp = new Cursor;
pInstance.store(tmp);
}
}
return *tmp;
}
};
atomic<Cursor*> Cursor::pInstance = 0;
mutex Cursor::m;
int main()
{
Cursor& c1 = Cursor::getInstance();
}
위의 소스코드와 같이 작성하면된다. atomic을 해석하는 부분은 구글을 검색해보기 바란다. 좀 자세하게 읽어 다룰 필요가 있기 때문에 여기서는 다루지 않는다. 기회가 된다면 포스팅을 정리해서 올리겠다. 가장 중요한 것은 memory reordering 동작을 막는 것이다.
Singleton의 일반화
Singleton 같은 경우 일반적으로 많이 사용한다. 따라서, 어떤 클래스를 구축할 때마다 Singleton의 코드를 추가하는 것이아니라 일반화를 시켜 구현을 해둔 후 가져다 쓰는 방식으로 이용한다. 일반화 하는 방식은 2가지가 존재한다.
- Macro (c 언어 방식)
- 상속 (c++ 언어 방식)
두가지 방식이 어떻게 다른지 확인해보자.
Macro 일반화
아래의 코드는 macro 기법을 통해 일반화한다. macro를 작성할 때, 소스코드가 길어지면 “" 를 통해 구별한다.
#include <iostream>
using namespace std;
#define MAKE_SINGLETON(classname)
private: \
classname() {} \
classname(const classname&) = delete; \
void operator=(const classname&) = delete; \
public: \
static classname& getInstance() \
{ \
static classname instance; \
return instance; \
} \
class Cursor
{
int x,y;
MAKE_SINGLETON(Cursor)
};
int main()
{
Cursor& c1 = Cursor::getInstance();
cout << &c1 << endl;
}
팁으로 알아두자. Macro 작성할 경우 (;)은 보통 붙이지 않는 방향으로 작성한다.
상속
#include <iostream>
using namespace std;
template<typename TYPE> class Singleton
{
int x,y;
protected:
Singleton() {}
Singleton(const Singleton&) = delete;
void operator=(const Singleton&) = delete;
public:
static TYPE& getInstance()
{
static TYPE instance;
return instance;
}
};
class Mouse : public Singleton < Mouse >
{
};
int main()
{
Mouse& c1 = Mouse::getInstance();
}
위의 코드는 상속을 통해 재사용하는 방법을 나타낸 것이다. Singletone을 상속받으면 객체 타입을 전달하면 된다. 다만, 일반적인 클래스로 작성할 경우 객체타입이 고정되기 때문에 객체 타입을 받을 수 있는 Template을 통해 구현해야한다. 이렇게 template을 이용해 파생클래스의 이름을 알 수 있는 방법을 CRTP (Curiously Recurring Template pattern) 이라고 부른다.
위의 패턴 같은 경우 안드로이드 프레임워크에서 사용하는 코드와 비슷한대, 여기를 클릭해서 확인해보자.
Singleton pattern은 많이 사용하니 자세하게 알아두는 것이 좋다. 모르겠으면, 처음부터 다시 한번 찬찬히 읽어보기 바란다.


